
The fundamental tension in generative video is not the creation of motion, but the preservation of matter. Any operator who has spent a few hours in a production-grade generative environment knows the frustration: you prompt a simple lateral pan, but as the camera moves, the background buildings begin to breathe, or the subject’s limbs liquefy into the surrounding environment. This phenomenon, often termed “temporal drift,” is the primary barrier to moving AI video from a novelty tool to a reliable asset in a professional creative pipeline.
For creative operations leads, the goal is not just “cool” movement; it is repeatable kinetic integrity. If a model cannot maintain the structural consistency of a character across a four-second clip while the camera rotates, that model is effectively useless for narrative or commercial work. To bridge this gap, we must look past the marketing reels and understand the mechanical friction between motion prompts and structural coherence.
The Physics of Hallucination: Why Movement Triggers Morphing
The current generation of video models operates on a fundamental paradox. They are trained on vast datasets of video, but they do not possess an internal physics engine or a 3D understanding of space. Instead, they rely on temporal consistency—the ability of the model to predict the next frame based on the pixel-level patterns of the preceding ones.
When we introduce high-velocity movement, we increase the statistical burden on the model. In a static shot, the model only needs to maintain the “idea” of a subject. But once that subject moves, or the camera pans, the model must re-calculate every pixel’s position in relation to a shifting perspective. This is where the hallucination rate spikes.
High-velocity movement, such as a fast drone shot or a running subject, often leads to “morphing artifacts.” Because the model is predicting based on pixel proximity rather than spatial awareness, it may mistake a fast-moving arm for part of the background, causing the two to merge. This is particularly noticeable in textures like fur, hair, or intricate textiles. It is worth noting that we are still in a period of significant uncertainty regarding how transformer architectures handle occlusion—the moment one object passes behind another. Even the most advanced engines frequently “forget” the shape of an object once it is briefly hidden from view, leading to anatomical collapses when it reappears.
Decoupling Camera Movement from Subject Action
A common mistake in early-stage AI video production is the “over-stuffed prompt.” Operators often describe the camera movement and the subject’s action in a single, continuous sentence. For example: “A man running through a forest while the camera circles him rapidly.”
This approach frequently leads to “prompt bleed,” where the model confuses the kinetic energy of the camera with the movement of the subject. The result is often a jittery subject whose body is reacting to the camera’s “wind” rather than its own internal physics. To mitigate this, a tactical framework requires treating the “virtual camera” and the “scene actor” as two separate variables in the prompt architecture.
By using a professional AI Video Generator, operators can begin to isolate these variables. A more successful strategy involves establishing the scene and the subject’s baseline state first, then applying specific camera directives using separate weighting or dedicated camera control tools.
There are, however, technical limits that no amount of clever prompting can currently overcome. For instance, most models struggle with complex “tracking shots” where the subject moves toward the camera while the camera moves away (a Dolly Zoom). The breaking point of a specific seed is usually reached when the model is asked to calculate two opposing vectors of motion simultaneously. In these cases, the subject often loses its skeletal integrity, becoming a blur of evolving textures.
Establishing a Kinetic Benchmark for Asset Pipelines
Creative operations leads building repeatable pipelines cannot rely on “getting lucky” with a seed. They need a motion stress test—a standardized set of prompts and movements used to evaluate whether a model or a specific update is production-ready.
A standard stress test should include:
- The Linear Pan: Moving the camera horizontally across a detailed background to check for “background breathing.”
- The Subject Articulation: Keeping the camera static while a human or animal subject performs a complex motor task, such as tying a shoe or turning a head 180 degrees.
- The Radial Move: A 360-degree rotation around a stationary object to test the model’s 3D consistency.
When building these pipelines, it is often more efficient to prioritize “low-motion” base shots. These clips have a higher probability of maintaining coherence and can be augmented in post-production with traditional stabilizing or motion-blur tools. The cost-to-quality ratio of regenerating a high-action shot 50 times to get one “clean” version is rarely defensible in a commercial setting. It is often more pragmatic to accept the limitation that generative models are currently better at cinematic, slow-motion “mood” shots than they are at high-octane action choreography.
Leveraging Model Diversity via Multi-Engine Platforms
The “winning” model for a specific project often depends entirely on the type of motion required. No single engine currently dominates every kinetic profile. Some models, such as Kling or Veo, have shown a remarkable ability to handle fluid, organic character movement. Others, like Runway or certain Sora-adjacent architectures, might excel at the cinematic textures of a slow-tracking landscape shot.
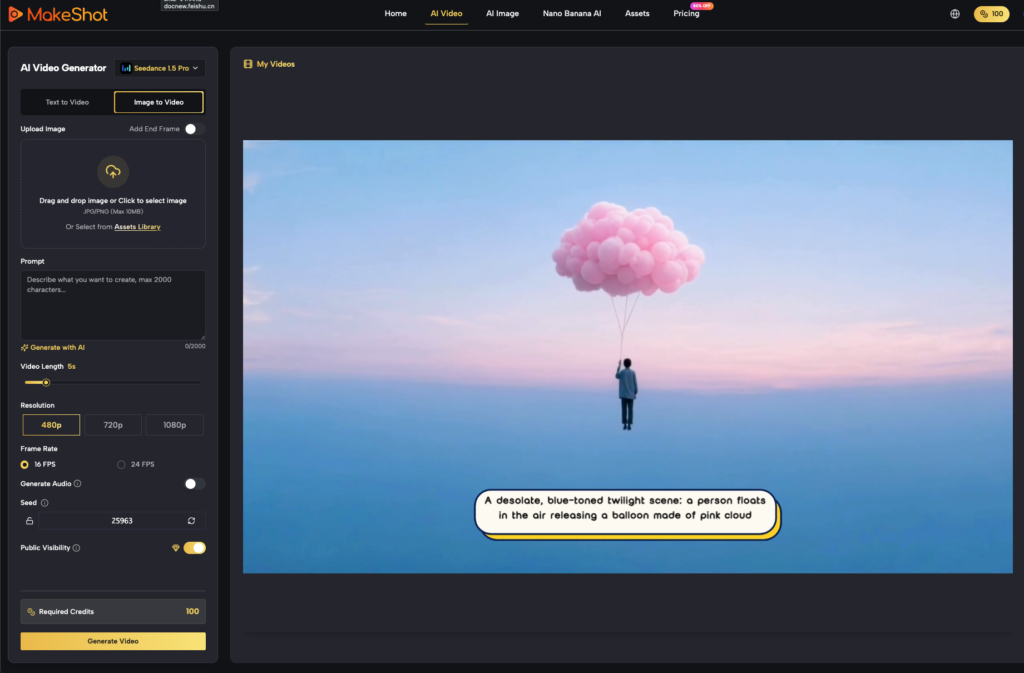
This is where a multi-model approach becomes a strategic advantage. Using an AI Video Generator within a unified interface like MakeShot allows teams to A/B test motion coherence across different underlying architectures without the friction of switching platforms. If a specific camera move—say, a crane shot—fails to render consistently in one model, the operator can immediately port the prompt and seed parameters into another engine to see if its “kinetic signature” handles the vector more gracefully.
MakeShot integrates models like Google Veo, Kling, and Runway, providing a sandbox where the primary goal is comparison rather than just creation. This capability is essential for creative ops because it removes the “vendor lock-in” that can cripple a project when a model update unexpectedly changes how it handles temporal consistency. The pragmatic advantage here is the ability to switch models mid-pipeline based on the specific kinetic demands of a scene.
See also: Harnessing the Sun: The Rise of Solar Water Pump Technology for Sustainable Agriculture
Uncertainty and the Limits of Temporal Consistency
Despite the rapid pace of development, we must maintain a level of skepticism regarding “perfect” AI video. The industry currently lacks a standardized, objective metric for “temporal drift.” While we have metrics for image quality (like Fréchet Inception Distance), measuring the “correctness” of motion remains a subjective human task. This means that for any professional output, human review is not just recommended; it is mandatory to catch the subtle anatomical errors that a model might overlook.
Furthermore, we are not yet at a point where a 60-second continuous action shot can be generated with 100% anatomical accuracy. Most professional workflows still rely on “stitching”—generating short, 2-to-4-second bursts of motion and editing them together to create the illusion of a longer sequence. This is a vital expectation-reset for any team looking to integrate AI into their workflow: the “one-shot” masterpiece is currently a statistical anomaly, not a repeatable business process.
We must also be wary of “cherry-picked” demo reels. A model that looks flawless in a 5-second clip of a cat walking may fail catastrophically when asked to render a human face during a complex emotional transition. The “motion coherence gap” is closing, but the final 10% of consistency—the part that prevents a viewer from feeling that something is “off”—remains the most difficult to bridge.
For the operator, the path forward is one of disciplined experimentation. By understanding the mechanical causes of motion artifacts and utilizing platforms that allow for cross-model benchmarking, creative teams can turn the chaos of generative video into a predictable, if still slightly temperamental, production tool. The goal is to move from being a “prompter” who hopes for the best, to an “operator” who understands exactly where the physics of a model will break and how to work around those fractures.



